
Overview
VOCOVID uses a Convolutional Neural Network (CNN) to identify if your cough recording shows symptoms of COVID-19. While it is intended to screen whether or not users may be presenting symptoms of COVID-19, it should be noted that VOCOVID is merely a screening tool, and all results cannot be considered an official diagnosis.
Mel-Spectrograms
Mel Spectrograms create a visual representation of the audio frequencies in a recording, helping identify restricted breathing or distinguishing between “wet” and “dry” coughs. The x-axis represents time, the y-axis represents frequency, and the color intensity represents amplitude. This method reduces data dimensionality, making it computationally efficient for our CNN.
Mel Spectrograms allow for efficient identification of COVID-19 cough patterns by focusing on specific audio frequencies and amplitudes. This also helps train the CNN more effectively by enhancing features needed for accurate testing.
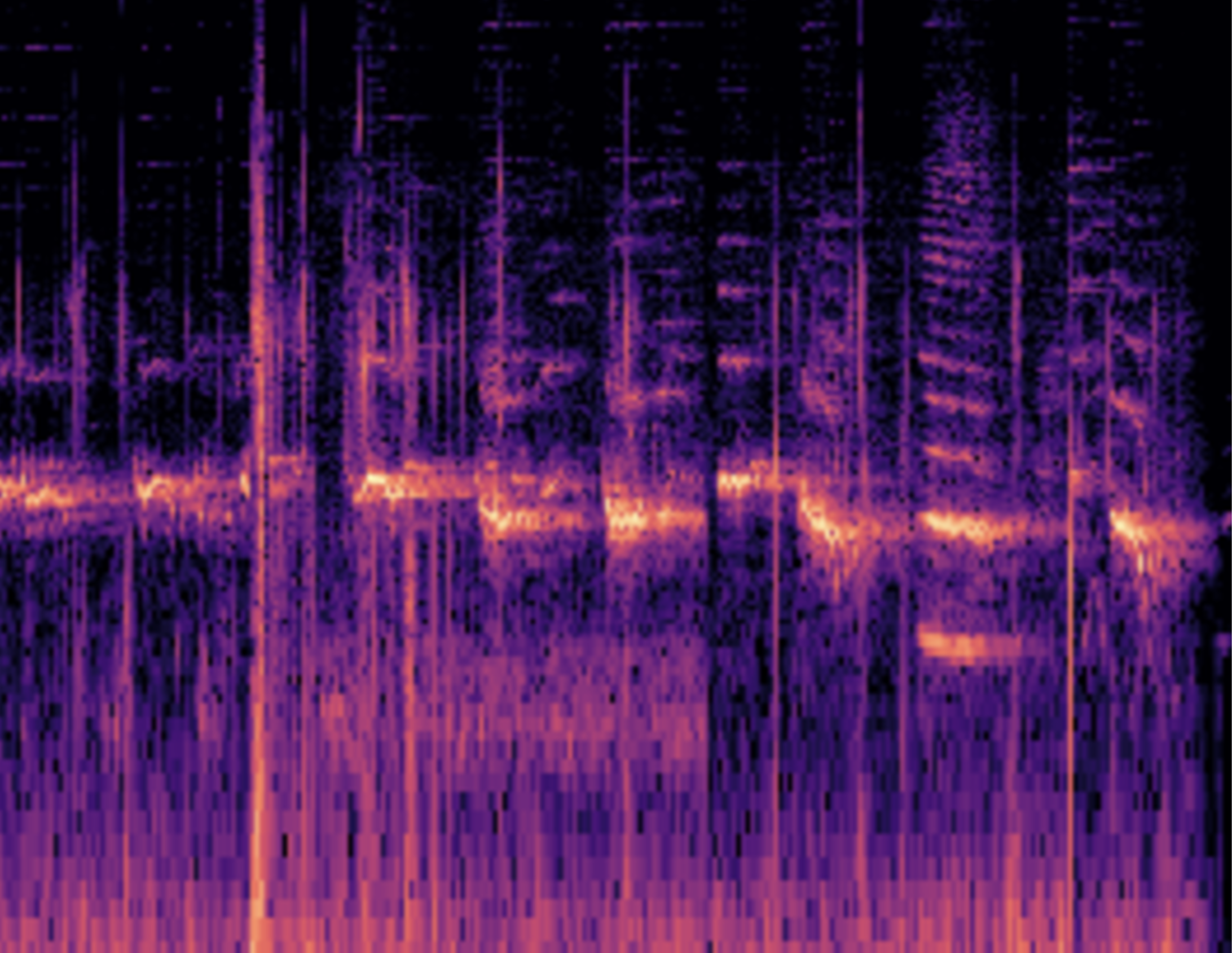
Hyperparameters
- Target Sample Rate: 22 050 Hz
- FFT Window Length: 2 048
- Hop Length for STFT: 256
- Number of Mel Bands: 256
- Max Frequency: 8 000 Hz
We trim each spectrogram to one cough 's duration to avoid background noise interference.
By compressing frequencies into the Mel scale, we lower our model 's computational load while focusing on the pitches humans actually hear.
Convolutional Neural Network
CNNs are the backbone of VOCOVID due to their ability to process Mel Spectrograms. Although CNNs can lose information in some cases, they are still preferred over RNNs for this project due to their ability to produce feature maps. These maps enable dataset augmentation and enhance key features for identifying COVID-19 symptoms in audio data.
Our Model Architecture
The VOCOVID model uses K-fold cross-validation and pre-processing on Mel-Spectrograms for training. Currently, the model has two layers for processing data during testing, with plans to increase complexity as testing progresses.
We built an Attention- Enhanced CNN with three convolutional blocks, followed by a classification head:
Block 1: Conv 3x3 (1→32) → BatchNorm → ReLU → MaxPool 2 x2 → Channel- Attention → Spatial- Attention
Block 2: Conv 3x3 (32→64) → BatchNorm → ReLU → MaxPool 2 x2 → Channel- Attention → Spatial- Attention
Block 3: Conv 3x3 (64→128) → BatchNorm → ReLU → MaxPool 2 x2 → Channel- Attention → Spatial- Attention
Head: AdaptiveAvgPool 1 x1 → Flatten → FC 128→64 → ReLU → Dropout 0.5 → FC 64→2 (logits)
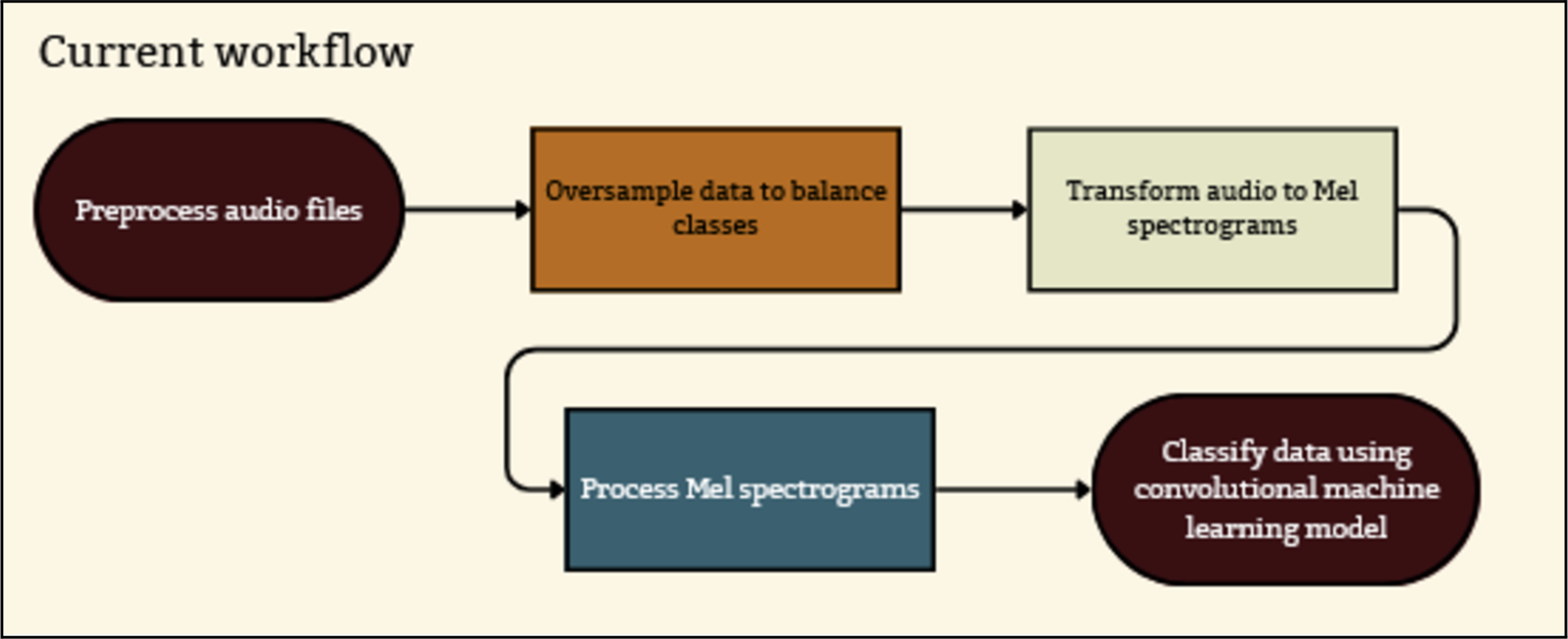
Current Machine Learning Workflow
ResNet50
ResNet50 serves as the benchmark model for VOCOVID due to its proven accuracy in audio data processing without requiring preprocessing for imbalance handling. Results from testing with ResNet50 on our dataset will be included soon.
Disclaimer: VOCOVID is a screening tool and cannot provide an official COVID-19 diagnosis. Please consult a medical professional for an official diagnosis.
Research as of 11/24/2024
- Wolf-Monheim, Friedrich. “Spectral and Rhythm Features for Audio Classification with Deep Convolutional Neural Networks.” 2024.
- Kexin Luo et al., “Croup and Pertussis Cough Sound Classification Algorithm,” Biomedical Signal Processing and Control, 2024.
- Ghrabli, Syrine et al., "Challenges and Opportunities of Deep Learning for Cough-Based COVID-19 Diagnosis," 2022.
- Awan, Mazhar et al., "Efficient Detection of Knee Anterior Cruciate Ligament Using Deep Learning," 2021.
- Mazerolle, Troy. “Using VGG16 to Classify Spectrograms.” Kaggle, 2023.
- Yadav, Jyoti et al., “Audiovisual Multimodal Cough Data Analysis for Tuberculosis Detection,” 2024.
- Dentamaro, Vincenzo et al., “AUCO ResNet: An End-to-End Network for COVID-19 Pre-Screening,” 2022.